

کاربردهای یادگیری عمیق
یادگیری عمیق (Deep Learning) در زمینه بینایی کامپیوتر (Computer Vision) انقلابی ایجاد کرده است. این فناوری به طور گسترده برای آموزش رایانه ها برای “دیدن” و تجزیه و تحلیل محیط به روشی مشابه انسان استفاده می شود. کاربردهای آن شامل خودروهای خودران، رباتیک، تجزیه و تحلیل داده و موارد بسیار دیگر است.
در این مقاله به طور مفصل به کاربردهای یادگیری عمیق برای بینایی کامپیوتر خواهیم پرداخت. اما قبل از آن، بیایید ببینیم که بینایی کامپیوتر و یادگیری عمیق چیست.
بینایی کامپیوتر چیست؟
بینایی کامپیوتر (CV) شاخه ای از هوش مصنوعی است که به رایانه ها امکان استخراج اطلاعات از تصاویر، فیلم ها و سایر منابع بصری را می دهد.
بینایی کامپیوتر به عنوان یک رشته علمی، درگیر تئوری ای است که پشت سیستم های مصنوعی که اطلاعات را از تصاویر استخراج می کنند، است. به عنوان یک رشته فناوری، بینایی کامپیوتر به دنبال اعمال تئوری های خود در توسعه سیستم های کاربردی بینایی کامپیوتر است. هدف کلی بینایی کامپیوتر توسعه سیستم هایی است که بتوانند به طور خودکار محتوای بصری را در زمینه های مختلف شناسایی، پردازش و تفسیر کنند تا وظایف را انجام دهند. از بینایی کامپیوتر برای نظارت تصویری، امنیت عمومی و اخیرا برای کمک به راننده در اتومبیل و اتوماسیون فرآیندهایی مانند تولید و لجستیک استفاده می شود.

یادگیری عمیق در بینایی کامپیوتر چیست؟
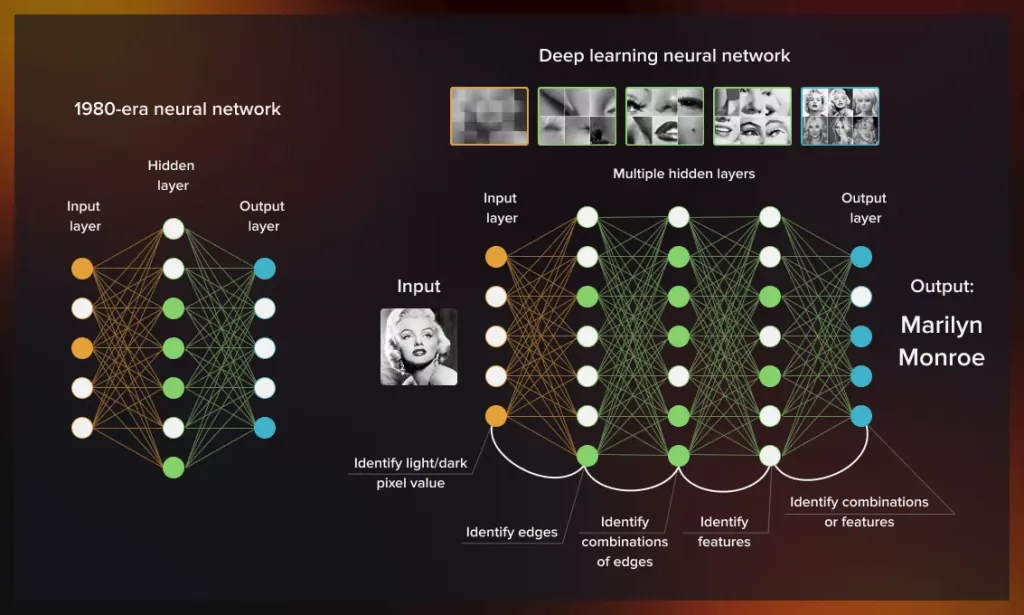
یادگیری عمیق (Deep Learning) یک روش یادگیری ماشینی است که بر اساس شبکه های عصبی مصنوعی (ANN) بنا شده است. یادگیری عمیق شامل آموزش شبکه های عصبی مصنوعی بر روی مجموعه داده های عظیم است. این شبکه ها از لایه های زیادی از واحدهای پردازش اطلاعات (نرون ها) تشکیل شده اند که به طور کلی از نحوه عملکرد مغز الهام گرفته شده اند.
هر نورون عمل ساده خود را بر روی ورودی از واحدهای دیگر انجام می دهد و خروجی خود را به واحدهای دیگر در لایه های بعدی ارسال می کند تا زمانی که به یک لایه خروجی با مقادیر پیش بینی شده برسیم. شبکه های عصبی عمیق می توانند پارامترهای زیادی داشته باشند (در برخی موارد بیش از 10 میلیون)، که به آنها امکان می دهد روابط پیچیده و غیرخطی بین ورودی ها و خروجی ها را بیاموزند.
انواع مختلف از شبکه های عصبی
مروج (Convolutional Neural Network – CNN): مهمترین نوع شبکه عصبی برای بینایی کامپیوتر است.کاربردهای یادگیری عمیق CNN ها با موفقیت در بسیاری از زمینه های مختلف مانند هوافضا و مراقبت های بهداشتی اعمال می شود.
مکرر (RNN)
متخاصم مولد (GAN)
بازگشتی
شبکه های عصبی کانولوشن چیست؟
شبکههای عصبی مروج (Convolutional Neural Network – CNN) نوعی از شبکههای عصبی مصنوعی هستند که از لایههای مروج (Convolutional Layer) تشکیل شدهاند. مزیت اصلی CNN ها این است که می توانند ویژگی ها را مستقیماً از مقادیر خام پیکسل یاد بگیرند بدون اینکه نیاز به ویژگی های مهندسی شده با دست یا دانش قبلی در مورد جهان داشته باشند.
از فرایند زیر برای تشخیص تصویر استفاده می شود. تصویری به شبکه داده می شود که از پیکسل تشکیل شده است. در اولین لایه مروج، فیلترهایی به هر پیکسل در تصویر اعمال می شود تا یک نقشه ویژگی ایجاد شود. سپس این نقشه به لایه دیگری از فیلترها وارد می شود که نقشه دیگری تولید می کند و به همین ترتیب ادامه می یابد تا لایه آخر پیش بینی خود را انجام دهد.
تاریخچه بینایی کامپیوتر
سال ۱۹۵۹: اولین اسکنر تصویر دیجیتال، تصاویر را به شبکه های عددی تبدیل کرد تا رایانه ها بتوانند تصاویر را تشخیص دهند.
دهه ۱۹۶۰: لارنس رابرتس، که به طور کلی پیشگام اینترنت و بینایی کامپیوتر محسوب می شود، بحثی را در مورد امکان استخراج داده های هندسی سه بعدی از تصاویر دو بعدی مطرح کرد. پس از آن، محققان زیادی روی کارهای بینایی سطح پایین مانند بخشبندی و تشخیص شروع به کار کردند.
دهه ۱۹۷۰: بر اساس این فرض که چشم انسان می تواند اجسام را با شکستن آنها به واحدهای اصلی تشکیل دهنده آنها تشخیص دهد، مفاهیم متعددی از جمله رویکردهایی برای ضبط و/یا ثبت اشیاء و شناسایی آنها بر اساس اجزای تشکیل دهنده، توسعه یافت.
دهه ۱۹۸۰: کنیهیکو فوکوشیما، دانشمند کامپیوتر ژاپنی، نئوکگنیترون را اختراع کرد که پیشرو شبکههای عصبی مروج (Convolutional Neural Network) مدرن است.

یادگیری عمیق چگونه در وظایف بینایی کامپیوتر به کار گرفته می شود؟
یادگیری عمیق با کمک شبکه های عصبی مروج (CNN) قادر است وظایف زیر را در بینایی کامپیوتر انجام دهد:
تشخیص اشیاء (تشخیص شیء): امروزه هوش مصنوعی قادر است اشیاء ساکن و متحرک را با دقت 99 درصد تشخیص دهد. این چگونه انجام می شود؟ به طور کلی، این کار با تقسیم تصویر به قطعات و اجازه دادن به الگوریتم ها برای یافتن شباهت ها با یکی از اشیاء موجود به منظور اختصاص دادن آن به یکی از کلاس ها انجام می شود.
تشخیص چهره (Face Recognition)
تشخیص حرکت (Motion Detection)
تخمین پوزیشن (Pose Estimation): تخمین موقعیت و حالت بدن انسان یا یک شیء دیگر در یک تصویر یا ویدیو
تقسیم بندی معنایی (Semantic Segmentation): تقسیم بندی هر پیکسل در یک تصویر به یک برچسب خاص، به طوری که برچسب نشان دهنده محتویات آن پیکسل باشد، برای مثال تفکیک آسمان از ساختمان و یا عابر پیاده از ماشین
طبقه بندی (Classification) در این فرآیند نقش مهمی ایفا می کند و موفقیت تشخیص اشیاء تا حد زیادی به غنی بودن پایگاه داده اشیاء بستگی دارد.
تشخیص اشیاء با رویکرد تک مرحله ای و دو مرحله ای
پیش از معرفی الگوریتم YOLO (You Only Look Once) تشخیص اشیاء به صورت دو مرحله ای انجام می شد. ابتدا تصویر به چندین باکس محدود تقسیم بندی می شد که روی اشیاء بالقوه تمرکز داشت. سپس بعد از آن، شناسایی اشیاء انجام می گرفت.
در رویکرد تک مرحله ای، شبکه در یک مرحله تصویر را بررسی و تشخیص می دهد. امروزه با توجه به هدف و اولویت ما که سرعت یا دقت است، می توانیم یکی از رویکردهای تک مرحله ای یا دو مرحله ای را انتخاب کنیم. به عنوان مثال، یک روش تشخیص اشیاء دو مرحله ای بهترین راه حل برای تجزیه و تحلیل ماموگرافی غربالگری بیمار است. در این مورد، دقت از سرعت مهمتر است. برعکس، لزومی ندارد که تمام جزئیات خودرویی که به طور مستقیم به سمت شما در حال رانندگی است را ببینید. در چنین شرایطی، کلید تشخیص اندازه و جهت شیء است تا دستیار رانندگی بتواند برای جلوگیری از تصادف ظرف چند ثانیه ترمز کند.
تشخیص چهره
اصول اولیه تشخیص چهره همان اصول تشخیص اشیاء است. تفاوت این است که تمرکز روی جزئیات لازم برای شناسایی چهره انسان در تصویر یا ویدیو تغییر می کند. برای این منظور از یک پایگاه داده گسترده از چهره ها استفاده می شود. جزئیاتی که توسط الگوریتم تجزیه و تحلیل می شوند عبارتند از:
محیط صورت (Contour of the Face)
فاصله بین چشم ها (Distance Between the Eyes)
شکل گوش و گونه (Shape of Ears and Cheekbones)
و …
پیچیده ترین قسمت این فرآیند، شناسایی همان فرد در زوایای مختلف، شرایط نوری متفاوت یا با ماسک یا عینک است. در حال حاضر، به شبکه های عصبی مروج آموزش داده می شود تا از یک نمایش کم بعدی از چهره های سه بعدی استفاده کنند که طبقه بندی کننده ها بر اساس آن پیش بینی های خود را انجام می دهند. این رویکرد پتانسیل دستیابی به دقت بالاتر از استفاده از تصاویر دو بعدی و سرعت عملکرد بیشتر نسبت به تشخیص ساده سه بعدی را دارد.
تشخیص چهره در مقابل تشخیص صورت
تشخیص چهره (Face Detection): تایید وجود چهره انسان در یک تصویر/ویدیو است. به عبارت دیگر، تشخیص چهره به سادگی به ما می گوید که آیا در یک تصویر یا ویدیو، چهره انسان وجود دارد یا خیر.
تشخیص صورت (Face Recognition): شناسایی یک فرد خاص شناخته شده برای سیستم از پایگاه داده است. تشخیص چهره اولین مرحله از فرآیند تشخیص صورت است.
با وجود اینکه تشخیص چهره می تواند بسیاری از فرآیندهای دنیای واقعی مانند کنترل های امنیتی و نظارت در فرودگاه ها را به طور قابل توجهی ساده کند، این فناوری همچنان بحث برانگیز است. مشکل این است که استفاده از داده های بازیابی شده از طریق تشخیص چهره همچنان بدون مقررات باقی مانده است، که نگرانی های مربوط به حریم شخصی را برانگیخته است.
نمونه بارز آن، سیستم اعتبار اجتماعی در بعضی از کشورها است که شامل تمام جنبه های زندگی شهروندان می شود و برای قضاوت در مورد “اعتماد” مردم استفاده می شود. داده های حاصل از سیستم های نظارتی در خیابان، همراه با اطلاعات بانک ها، سازمان های دولتی و سایر موسسات توسط یک مرکز متمرکز تجزیه و تحلیل می شود. بر اساس آن، شهروندان امتیاز اعتباری دریافت یا از دست می دهند که بر توانایی آنها برای دریافت کار و مزایای اجتماعی تأثیر می گذارد.
در ایالات متحده، استفاده از تشخیص چهره توسط مجریان قانون یک موضوع مهم است. به همین دلیل، در نوامبر 2021، فیس بوک تعطیلی سیستم تشخیص چهره خود را اعلام کرد و داده های اسکن چهره بیش از 1 میلیارد کاربر را حذف کرد.
تشخیص پوزیشن بدن (Pose Estimation)
تشخیص پوزیشن بدن انسان به دلیل تنوع زیاد در شکل و ظاهر انسان، نورپردازی دشوار و محیط های شلوغ، یک کار چالش برانگیز در بینایی کامپیوتر است. برای این کارها از عکس، توالی تصاویر، تصاویر عمق یا داده های اسکلتی از دستگاه های ضبط حرکت برای تخمین موقعیت مفاصل بدن استفاده می شود. پیش از ظهور یادگیری عمیق، تخمین پوزیشن بدن بر اساس شناسایی اجزای بدن انجام می شد.
تشخیص پوزیشن بدن انسان شامل تشخیص موقعیت و جهت بدن فرد از یک تصویر یا توالی تصاویر است. این کار را می توان با استفاده از یک تصویر واحد انجام داد، اما اغلب برای بهبود دقت و ثبات، با استفاده از نقاط متعدد برای گرفتن اندام های مختلف بدن انجام می شود.
تقسيم بندی معنایی (Semantic Segmentation)
تقسیم بندی معنایی نوعی از یادگیری عمیق است که تلاش می کند هر پیکسل در یک تصویر را به یکی از چندین کلاس مانند جاده، آسمان یا چمن طبقه بندی کند. سپس از این برچسب ها در طول آموزش استفاده می شود تا زمانی که تصاویر جدید پردازش می شوند، آنها نیز بر اساس آنچه به نظر می رسد در مقایسه با تصاویر دیده شده قبلی، به این دسته ها تقسیم شوند.
هدف کلی تقسیم بندی معنایی، جدا کردن اشیاء از پس زمینه است. این کار در خودروهای خودران، تعامل ربات و انسان، یا سایر برنامه های کاربردی بینایی کامپیوتر که درک آنچه در تصویر اتفاق می افتد در عین حال حذف نویزها از اهمیت بالایی برخوردار است، مفید است.
چالش های کلیدی یادگیری عمیق در بینایی کامپیوتر
با وجود اینکه بینایی کامپیوتر اخیراً پیشرفت قابل توجهی داشته است، اما همچنان چالش های عمده ای وجود دارد که محققان باید حل کنند.
یکی از آنها تشخیص موقعیت اشیاء است (Object Localization). هوش مصنوعی نه تنها باید قادر به دسته بندی اشیاء باشد، بلکه باید موقعیت آنها را نیز تعیین کند. همچنین، الگوریتم ها برای برآوردن نیازهای پردازش ویدیو در زمان واقعی، باید تشخیص اشیاء را بسیار سریع انجام دهند.
یکی دیگر از مشکلات دشوار در بینایی کامپیوتر که هنوز حل نشده است، تشخیص صحنه (Scene Recognition) است. این کار شامل چندین زیرمجموعه است که نیاز به پاسخ به سوالات زیر دارد:
در یک تصویر چه اتفاقی می افتد؟
عناصر بصری و ساختاری صحنه چیست؟
این عناصر چگونه با هم مرتبط هستند؟
راه حل این مشکل با جنبه دیگری پیچیده می شود. در محیط های زمان واقعی، ورودی دوربین اغلب بر اساس مجموعه ای از خطوط است که به طور مداوم از سنسور می رسد. از آنها برای به روز رسانی تصویری استفاده می شود که دائماً در حال تغییر روی صفحه است. الگوریتم ها می توانند تحت تأثیر عوامل مختلفی مانند تریلر کامیونی جلوی یک ماشین سردرگم شوند.

مشکل دیگری تفسیر صحیح صحنه شناخته شده است: آیا شیء در حال رسیدن است یا ترک میکند، در حال باز شدن است یا بسته شدن در. برای طبقه بندی صحیح رویدادها، باید اطلاعات بیشتری به سیستم داده شود، که به دلیل کمبود داده یا قابلیت های محدود همیشه ممکن نیست.
یکی از موانع اصلی در بینایی کامپیوتر، مقدار کم داده های برچسب گذاری شده است که در حال حاضر برای تشخیص اشیاء در دسترس است. مجموعه داده ها به طور معمول شامل نمونه هایی برای حدود 12 تا 100 کلاس شیء هستند، در حالی که مجموعه داده های طبقه بندی تصویر می توانند تا 100000 کلاس را شامل شوند. برونسپاری اغلب تگ های دسته بندی تصویر رایگان (به عنوان مثال، با تجزیه متن شرح های ارائه شده توسط کاربر) ایجاد می کند. با این حال، ایجاد bounding box ها و برچسب های دقیق برای تشخیص اشیاء همچنان بسیار زمان بر است.
روشهای یادگیری عمیق پیشرفته برای بینایی کامپیوتر
برای حل چالشهای بینایی کامپیوتر که در بالا ذکر شد، محققان همچنان روی طیف وسیعی از روشهای پیشرفته کار میکنند. این روشها عبارتند از:
یادگیری سرتاسری (End-to-End Learning): این رویکرد برای شبکههای عصبی عمیق (NN) استفاده میشود که برای حل یک کار پیچیده بدون تفکیک آن به زیرکارها آموزش میبینند. مزیت اصلی این روش این است که فرآیند یادگیری توسط خود شبکه عصبی کنترل میشود، به این معنی که یک سیستم کاملاً خودآموز است.
یادگیری یک مرحلهای (One-Shot Learning): این روش مبتنی بر یک مسئله ارزیابی تفاوت است و به این معنی است که برای فرآیند یادگیری تنها به یک یا چند مثال آموزشی نیاز است (برخلاف هزاران مورد در مدلهای طبقهبندی). چنین سیستم بینایی کامپیوتر میتواند به دو تصویری که هرگز ندیده است نگاه کند و تعیین کند که آیا آنها یک شیء را نشان میدهند یا خیر.
یادگیری بدون نمونه (Zero-Shot Learning): در این حالت، به یک مدل یاد داده میشود تا اشیایی را که قبلاً ندیده است را تشخیص دهد. روشهای بدون نمونه، دستههای مشاهدهشده و مشاهدهنشده را از طریق برخی اطلاعات کمکی مرتبط میکنند. برای مثال، فرض کنید مدلی برای تشخیص اسبها آموزش دیده باشد، بدون اینکه هرگز یک گورخر را دیده باشد. این مدل میتواند گورخر را شناسایی کند در صورتی که بداند گورخرها شبیه اسبهای راهراه سیاه و سفید هستند.
کاربردهای بینایی کامپیوتر در صنایع مختلف
بینایی کامپیوتر به طور فزایندهای در طیف گستردهای از صنایع از جمله حملونقل، مراقبتهای بهداشتی، ورزش، تولید، خرده فروشی و غیره مورد استفاده قرار گرفته است. در این بخش به برخی از برجستهترین نمونهها خواهیم پرداخت.
حملونقل
به لطف یادگیری عمیق، سیستمهای تحلیل ترافیک در مقیاس بزرگ را میتوان با استفاده از دوربینهای نظارتی نسبتاً ارزان اجرا کرد. با افزایش دسترسی به حسگرهایی مانند دوربینهای مدار بسته، لیدار (تشخیص نور و اندازهگیری فاصله) و تصویربرداری حرارتی، شناسایی، ردیابی و دستهبندی وسایل نقلیه در جاده امکانپذیر است.
فناوریهای بینایی کامپیوتر برای تشخیص خودکار تخلفاتی مانند سرعت غیرمجاز، عبور از چراغ قرمز یا علائم ایست، رانندگی در خلاف جهت و دور زدن غیرمجاز استفاده میشوند.
شبکههای عصبی کانولوشنال (CNN) همچنین به توسعه روشهای مؤثر تشخیص اشغال بودن پارکینگ کمک کردهاند. مزیت تشخیص پارکینگ مبتنی بر دوربین، استقرار در مقیاس بزرگ، نصب و نگهداری کمهزینه است.
مراقبتهای بهداشتی
در پزشکی، از بینایی کامپیوتر برای تشخیص سرطان پوست و سینه استفاده میشود. به عنوان مثال، تشخیص تصویر به دانشمندان این امکان را میدهد که حتی تفاوتهای کوچک بین تصاویر سرطانی و غیر سرطانی را در اسکنهای MRI تشخیص دهند.
مدلهای یادگیری عمیق برای تشخیص شرایط جدی مانند سکته مغزی قریبالوقوع، اختلالات تعادل و مشکلات راه رفتن بدون نیاز به معاینه پزشکی به کار میروند.
تخمین پوزیشن بدن به پزشکان کمک میکند تا با تجزیه و تحلیل حرکات بیماران، آنها را سریعتر و دقیقتر تشخیص دهند. همچنین میتوان از آن در فیزیوتراپی استفاده کرد. بیمارانی که از سکته مغزی و آسیبدیدگی بهبود مییابند به نظارت مداوم نیاز دارند. برنامههای توانبخشی مبتنی بر بینایی کامپیوتر در آموزش اولیه مؤثر هستند و اطمینان حاصل میکنند که بیماران حرکات را به درستی انجام دهند و از آسیبهای بیشتر جلوگیری کنند.
تولید
بینایی کامپیوتر جزء حیاتی از تولید هوشمند است. برای مثال، به بازرسی خودکار وسایل ایمنی شخصی مانند ماسک و کلاه ایمنی کمک میکند. در کارگاههای ساختمانی و کارخانهها، بینایی کامپیوتر به نظارت بر رعایت رویههای ایمنی کمک میکند.
کاربردهای دوربین هوشمند، روشی مقیاسپذیر برای یکپارچهسازی بازرسی بصری خودکار و کنترل کیفیت خطوط تولید و مونتاژ ارائه میدهد. بازوهای رباتیک با قابلیت تشخیص اشیاء از نظر دقت، سرعت، بهرهوری و قابلیت اطمینان، به طور قابل توجهی از انسانها عملکرد بهتری دارند.
خرده فروشی
الگوریتمهای یادگیری عمیق میتوانند ترافیک مشتری را در فروشگاههای خرده فروشی کنترل کنند. آنها میتوانند زمان صرفشده در مکانهای مختلف و صف، تعیین بهترین مکانها برای توزیع نمونه رایگان و ارزیابی کیفیت خدمات را شناسایی کنند. از تمام این دادهها برای تجزیه و تحلیل رفتار مشتری به منظور بهینهسازی طراحی فروشگاه خرده فروشی و اندازهگیری عینی شاخصهای کلیدی عملکرد در مکانهای مختلف استفاده میشود. الگوریتمهای بینایی کامپیوتر همچنین برای امنیت مفید هستند. آنها میتوانند به طور خودکار محیط را برای تشخیص فعالیتهای مشکوک مانند دسترسی به مناطق ممنوعه یا سرقت تجزیه و تحلیل کنند.
نتیجه گیری
یادگیری عمیق برای بینایی کامپیوتر یک حوزه تحقیقاتی بسیار امیدوارکننده است که به حل طیف وسیعی از مشکلات دنیای واقعی و سادهسازی فرآیندهای مختلف در مراقبتهای بهداشتی، ورزش، حملونقل، خرده فروشی، تولید و غیره کمک میکند.
این زمینه در حال توسعه است و برخی از مسیرهایی که بیشترین پتانسیل را دارند شامل موارد زیر است:
-ادغام متن یا شیء در یک تصویر
-ارتقاء کیفیت تصاویر (Upscaling)
-حذف اشیاء نامرتبط از تصاویر (مانند کابلها یا علائم راهنمایی و رانندگی در مناظر شهری)
-انتقال استایل
کاربردهای یادگیری های عمیق در هایک ربات
با توجه به تکنولوژی پیشرفتهای که هایک ربات در زمینهی بینایی ماشین ارائه میدهد، میتوانیم به بررسی چگونگی یکپارچهسازی یادگیری عمیق در سیستمهای بینایی Hikrobot بپردازیم:

Vision Master (VM)
نرمافزار VM، که توسط هایک ربات توسعه داده شده است، به کاربران امکان ایجاد برنامههای بینایی و حل چالشهای بازرسی تصویری را میدهد. این نرمافزار شامل ماژولهای الگوریتمی متنوعی است که شامل موارد زیر میشود:
طبقهبندی
شناسایی اشیاء در دستههای از پیشتعیین شده.
تشخیص هدف
مکانیابی اشیاء خاص در تصویر.
تشخیص و مکانیابی کاراکترها
استخراج اطلاعات متنی.
جداسازی
جدا کردن اشیاء از پسزمینه.
رابط گرافیکی برای انجام عملیات توضیح داده شده، از جمله جمعآوری دادهها، آموزش مدلها و تشخیص، در VM وجود دارد.
VM برای کاربردهایی مانند موقعیتیابی تصویری، اندازهگیری ابعاد، تشخیص عیوب و استخراج اطلاعات متنی مناسب است.
ابزارهای یادگیری عمیق
ابزارهای یادگیری عمیق هایک ربات برای وظایف خاص طراحی شدهاند:
طبقهبندی DL
دستهبندی اشیاء بر اساس ویژگیهای آنها.
تشخیص اشیاء DL
مکانیابی و شناسایی اشیاء.
مکانیابی کاراکتر DL
مکانیابی دقیق کاراکترها یا متن.
تشخیص کاراکتر (OCR/OCV) DL
استخراج اطلاعات متنی.
این ابزارها از الگوریتمهای یادگیری عمیق با عملکرد بالا استفاده میکنند و قابلیت سفارشیسازی برای سناریوهای مختلف تشخیص را دارند.
مکانیابی و پیشبینی کارآمد
ابزارهای مکانیابی VM
مشکلات ترجمه، چرخش، بزرگنمایی و تغییر نور را حل میکنند. آنها به سرعت و با دقت اشیاء هندسی (مانند دایره) را تشخصی می دهند.
الگوریتم یادگیری عمیق
نقصها، موقعیتهای متن و دستهبندی اشیاء را درون تصاویر پیشبینی میکند. نقشههای حرارتی بر اساس نمونههای عادی، مکانهای غیرعادی را نشان میدهند.
رابط گرافیکی و سهولت استفاده
رابط کاربری تعاملی گرافیکی VM توسعه راهحل را ساده میکند. آیکونهای شهودی، Drag and Drop و گردش کار منطقی، فرآیند ایجاد راهحل بصری سریع را تسهیل میکنند.
به طور خلاصه، ادغام یادگیری عمیق هایک ربات در سیستمهای بینایی ماشین، اتوماسیون، کنترل کیفیت و بهرهوری را در صنایع مختلف بهبود میبخشد. ️️

